
The last post in this series covered the receipt of the Retro-CGA prototype circuit boards, and the soldering of all components onto one of the boards, making a completed prototype card:

This post covers the last step in preparing the card for use; the derivation of the character ROM and the loading of the character data into the ROM chip on the card.
Why do we need to load the card with characters? As it turns out, the original CGA card stored fonts locally on a dedicated ROM chip, instead of needing to search/retrieve from system memory. It’s possible this was done in order to reduce the overall load on the system memory bus; there would otherwise need to be constant traffic on the memory bus as the the screen contents were refreshed and the video DRAM cycled.
This means there is no way to change the inherent font that is used by the system, unless the ROM chip is altered and replaced. You might already be familiar with the font that the CGA card uses; it can still be seen in some modern computer BIOS screens.
In order for the Retro-CGA to work correctly, there will need to be some font information loaded into the character ROM chip on the card.
Legality:
Some readers are likely to spasm at this point and say “But you can’t copy ROMs tho! Call the police!”. This turns out to be true, but probably not in the way you are expecting: the ROM chip on the original CGA is a legacy part, custom fabricated for IBM. This chip does not feature in the list of compatible parts for the TL866II PLUS programmer that I’m using. So even if I wanted to, I couldn’t easily copy the ROM contents from the original CGA without some special trickery that I can’t be bothered performing.
Instead, the approach I’ll take is to assemble my own binary file to flash into the AT28C64 EEPROM chip on the Retro-CGA. The tricky part will be guessing how the font is mapped to the address space within the chip.
By creating the binary file myself, I hope to avoid the legal grey area that may come from copying from the original CGA directly. Some may say that the visual aspect of the CGA font itself is copyrighted but to that I say “ppffffff” and wave my hands in the air.
By creating the binary file myself, I would have the freedom to implement any particular font that I choose, including any open-source fonts that mimic the original CGA.
Font Structure:
Let’s start by inspecting the symbol for the character ROM as featured in the original CGA schematics:

There are some clues here based on the way that the address lines are hooked up:
- The address lines are numbered from A0 to A12; implying thirteen total bits of address space i.e. 8192 total address locations (including zero).
- There are eight output pins, implying that each address location contains eight bits of data.
- The lowest three bits of address space are connected to “+RA0″, +RA1” and “+RA2”. These are the raster address lines from the 6845 CRT controller. Three address lines gives eight possible values of control (including zero). Based on how the CRT controller behaves, these addresses are highly likely to correlate to the eight rows of each 8×8 character stored in ROM (raster address is related to horizontal scanline).
- The address lines “A11” and “A12” are tied high to +5 Volts. This implies that any memory location less than 6144 is completely inaccessible. Only one quarter of total address space is used. A bit odd.
- The first row of the first character is likely to reside at memory address 0b1100000000000, which is decimal 6144.
- The last row of the first character is likely to reside at memory address 0b1100000000111, which is decimal 6151.
- The first row of the second character is likely to reside at memory address 0b1100000001000, which is decimal 6152.
- The last row of the second character is likely to reside at memory address 0b1100000001111, which is decimal 6159.
- If this trend continues, there will be 256 characters contained in the 2049 memory locations accessible.
- If eight rows of each character are controlled by the CRT controller, and there are eight bits of width to each address location, then the pixels contained in each character symbol are likely described by an 8×8 bit map i.e. a “filled” pixel in a character symbol is likely represented by a “1” and a transparent pixel in each character symbol is likely represented by a “0”.
Independently of the schematic, we can learn from Wikipedia that the original IBM PC was designed to use Code Page 437. This gives us a good idea of the way that symbols are likely to be ordered (i.e. Character “$” being the 37th symbol in the sequence).
Based on all of these clues, I am supposing that the character data is stored as follows (using the upper-case “A” character as an example):
| Address Location | Data Byte |
| 0b1101000001000 (1A08)(6664) | 0b00110000 |
| 0b1101000001001 (1A09)(6665) | 0b01001000 |
| 0b1101000001010 (1A0A)(6666) | 0b10000100 |
| 0b1101000001011 (1A0B)(6667) | 0b10000100 |
| 0b1101000001100 (1A0C)(6668) | 0b11111100 |
| 0b1101000001101 (1A0D)(6669) | 0b10000100 |
| 0b1101000001110 (1A0E)(6670) | 0b10000100 |
| 0b1101000001111 (1A0F)(6671) | 0b00000000 |
Bolt text added for emphasis; you may be able to spot the “A” in the data bytes.
If this assumption is correct, we can simply fill a binary file with sequential bytes representative of the pixels contained in the row of each symbol.
Method of conversion:
For my particular circumstance the easiest method of conversion from font to binary that I could think of was to take a PNG image representing the font, convert each row of the character symbols into bytes, and then stuff them sequentially into a binary data file.
Reading a PNG would allow for some flexibility in creating future fonts; I would only need to alter the image as desired and then re-convert into the binary file.
The programming language of choice in this scenario was MATLAB (please stop groaning and rolling your eyes). Note that Octave is a free open-source alternative to MATLAB. I would like to use Python, but I haven’t quite figured out how to set up an IDE on Windows. MATLAB will have to do for now.
Font Image:
Trawling the internet I came across a post by reenigne on the VCF Forums in which he describes the various changes that he would make to the original CGA as part of a “Fantasy CGA redesign”. Maybe there are a few hints for myself that I could incorporate into the Retro-CGA later on.
In his post, reenigne links to an image hosted on his website that claims to show the CGA character map as a PNG image represented by black and white pixels. The overall size of the image is 128*512 pixels, with each pixel representing the 65536 bits of storage or 8192 address locations of 8bit data. I’ve shamelessly taken that image, and blanked the content below address 6664 that cannot be used in normal operation:

I also added little coloured squares in the background to keep track of the 8*8 character boundaries. I’ll use this image as the basis for the MATLAB program that converts the font pixel data into a binary file.
The Code:
The code didn’t take all that long to write, but as a consequence it is very crude. Not my best effort, but hey it works. I have no idea how resilient it is to errors so use at your own risk.
Behold the MATLAB code in all its glory:
format long g
clear all
close all
clc
[A,map]=imread('text_map.png');
image(A);
axis equal;
[Image_size_y,Image_size_x,Image_size_z] = size(A);
Char_row_qty = Image_size_y/8;
Char_col_qty = Image_size_x/8;
Bin_array = zeros(1,(Char_col_qty*Image_size_y));
Bin_array_index = 1;
character_array = zeros(8,8);
character_array_filtered = zeros(8,8);
byte_array = zeros(1,8);
byte_value = 0;
for char_row_index=1:Char_row_qty,
for char_col_index=1:Char_col_qty,
character_array = A((((char_row_index*8)-7):(char_row_index*8)),...
(((char_col_index*8)-7):(char_col_index*8)));
character_array_filtered = zeros(8,8);
for character_array_row=1:8,
for character_array_column=1:8,
if (character_array(character_array_row,...
character_array_column)==255),
character_array_filtered(character_array_row,...
character_array_column) = 1;
end
end
end
for character_array_row=1:8,
byte_value = 0;
byte_array = character_array_filtered(character_array_row,:);
byte_value = byte_value + (byte_array(1,1)*(2^7));
byte_value = byte_value + (byte_array(1,2)*(2^6));
byte_value = byte_value + (byte_array(1,3)*(2^5));
byte_value = byte_value + (byte_array(1,4)*(2^4));
byte_value = byte_value + (byte_array(1,5)*(2^3));
byte_value = byte_value + (byte_array(1,6)*(2^2));
byte_value = byte_value + (byte_array(1,7)*(2^1));
byte_value = byte_value + (byte_array(1,8)*(2^0));
Bin_array(1,Bin_array_index) = byte_value;
Bin_array_index = Bin_array_index + 1;
end
end
end
fileID = fopen('output.bin','w');
fwrite(fileID,Bin_array);
fclose(fileID);The code starts out by importing the PNG image into an array through the “imread” function. Each entry in the array “A” represents a colour value of the corresponding pixel in the image. The code shows a snapshot of the PNG file contents that it has read using “image(A);”, so that it can be checked for errors. The code then loops through each relative 8*8 character location and searches each pixel in the 8*8 array for a colour value of 255 (i.e white). When it sees a white pixel, it fills a corresponding 8*8 array with a value “1”. Each row of the 8*8 array is then scanned and converted into byte values, which are stored in yet another array. “Bin_array” is then converted to a binary file by writing with “fwrite”. The binary file is located in the same directory as the matlab “.m” script was run.
The Results:
After running the MATLAB script, we are left with a binary file that is supposed to represent the white glyphs contained in the PNG image file. One way to check this is to open the binary file in a hex editor:
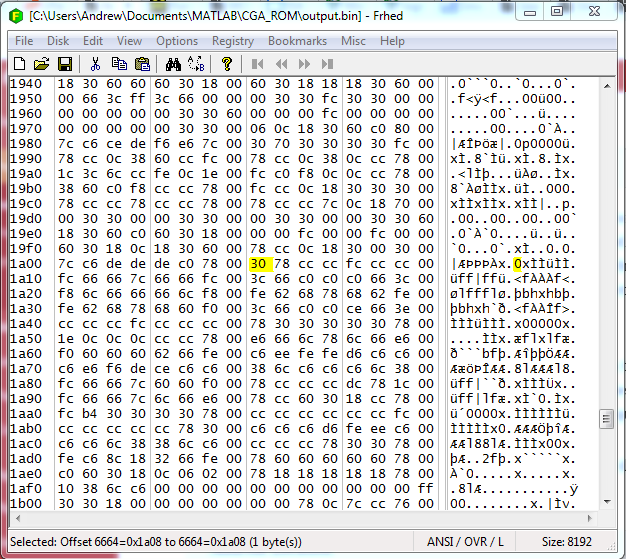
The first thing to notice is that the total size is displayed in the bottom right hand corner: 8192 bytes which matches our assumption about the memory address space. Good so far.
Scrolling to address offset 6664 reveals a hex value of “30” which is 0b00110000, which appears to show the the top two pixels in the top row of the “A” character. Hooray.
We appear to have created a binary file that we need to load into the character ROM of the Retro-CGA.
Loading the Binary:
The method for loading the binary file into the Character ROM will be very similar to the method that I used to load the BIOS into Sergey’s Micro 8088 board (See halfway down my post on Building the Micro 8088 and Backplane).
The only difference this time around is that I will use the TL866II PLUS programmer software to select the device “AT28C64B” which is the variant of ROM chip that I happen to be using. Obviously I would choose the binary file containing the character information to flash into the ROM chip.
Thankfully all went to plan, and I should now have a viable character ROM loaded onto the Retro-CGA.
Conclusion:
After a lot of assumptions and some below-average MATLAB code, the process of loading a character ROM onto the Retro-CGA should be complete. There will be no real way of knowing if this has worked until I test the overall card. I hope you, the reader, have enjoyed following along with this process.
In theory, we are ready to test the Retro-CGA for the first time. The next post in this series will hopefully document that process. Exciting! I hope you will join me for the next instalment in this series.
Very interesting and promising project! I really like to build one to implement in the micro 8088 🙂
Bastiaan
Hey! Great project. Since CGA cards are pretty rare here in Germany, this would be a very neat addition to the homebrew retro community. Will you be putting up the Gerber files so people can build their own versions? I would be very interested in doing something like that.
Hi Arne,
Thank you for your interest and words of encouragement 🙂 I am aiming to upload the Gerber files in the future. It may seem the project has been abandoned but I am slowly working on it in the background. I have verified that the Font ROM works nicely, and I’ve been able to get the 8088MPH demo working with some minor graphical differences (as expected, due to FE2010/FE2010A chip on the Micro8088 not being exactly the same as original IBM XT). A lot of the delay releasing Gerbers has been because of developments I am trying to make to the design to make small improvements where possible e.g. expanding registers from 6 to 8 bits to allow font bank switching. I’m currently trying to develop a circuit to allow the use of modern (more widely available) RAM. It also takes quite a lot of energy to write up blog posts showing this progress. If development of these various improvements drags on too long I will most likely release the Gerbers without them, so people at least have something to build and enjoy.
P.s. I’ve noticed a thread on Twitter which you may have contributed to, as @root42? To answer the question there; the original IBM CGA is indeed a four-layer board. I assume from the outset that IBM was forced to align chips vertically due to space constraints on the board profile. Ironically, by aligning all chips vertically, it made it extremely difficult to route traces horizontally along the board due to the restricted spacing between chip pins. From what I can gather: top layer is for horizontal traces, bottom layer is for vertical traces, one internal layer is ground, and the other internal layer is 5V. One of the internal layers (I think 5V) shares routing for about a dozen traces from one end of the board to the other, because there is no way to do so otherwise. Beyond that reason, I’ve noticed that the four layer design is very beneficial because signal cross-talk is a problem in this design. Some of my first prototype boards had a stackup with signal layers adjacent to one another and it caused noticeable graphical jitter (horizontal pixel timing seemed to be affected by some other part of the circuit). Although a four layer design is more expensive I think it is necessary/beneficial to keep graphical jitter to a minimum.
P.p.s. Exciting to have this page mentioned on Twitter, hello out there whoever is reading this! If @TubeTimeUS is reading, I have greatly enjoyed watching your assistance with CuriousMarc on the Apollo hardware videos
hello.
This is good project. and full. you try more. and spend more time.
but I had idea for this CGA card.
my idea: change old D-RAM chip with one new SD-RAM 512KB, and if may be combine or delete few of other chip that do not need.
circuit had to small size…
I read all post about CGA carefully. it is good project an do nice.
but it is better change with new chip for simple and sample and easy to assemble and use.